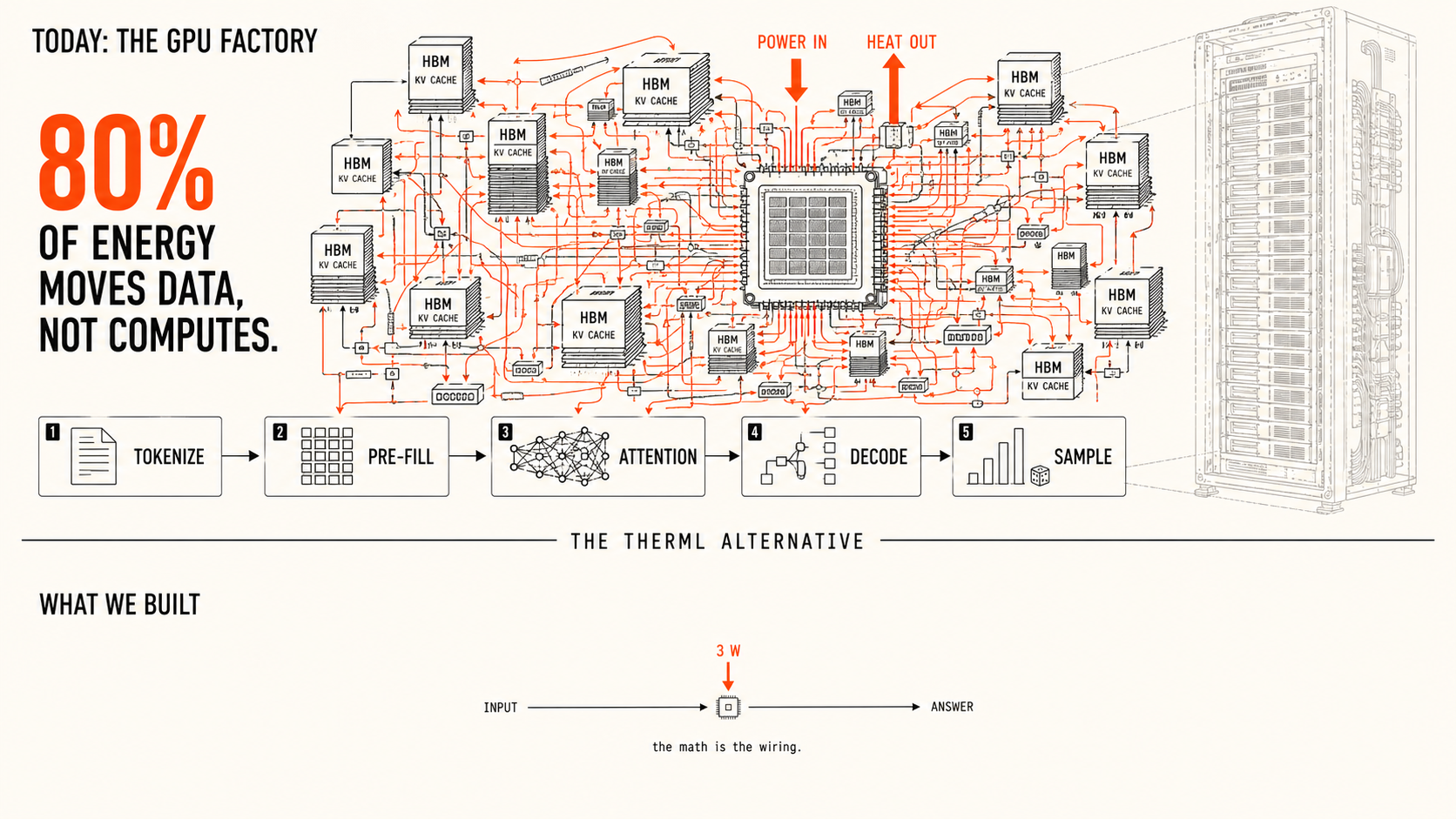
Today's GPU factory and the alternative we built. Schematic by Therml.
The Hamster Wheel
Most of the electricity in an AI datacenter does not compute anything; it just moves numbers around. We built a chip that does not have to.

Alex Morisse
Founder & CEO · April 25, 2026 · 3 min read
Somewhere outside Ashburn, Virginia, there is a building the size of a small town that exists for one reason: to answer your questions to a chatbot. It uses as much electricity as a city, and the cooling alone draws a small river through pipes in the floor.
When you type a question into the chat window, what happens inside that building is, on inspection, absurd. The building's job is to predict the next word in your reply, and it does this by looking up several hundred billion numbers from a row of memory chips, walking each one across a small piece of silicon, multiplying it by a different number, adding the result, and writing it back to memory. Then it does the same thing again for the next word, and the next, and the next, until the answer is finished.
Most of the energy is the walking. Eighty percent of the electricity inside that building does not compute anything; it just moves numbers around. Imagine a kitchen where the cook walks to the pantry, the fridge, the spice rack, and the dishwasher for every single bite of food they prepare. Most of the calories in the kitchen are spent on the walking, the food eventually gets made, and you would be hard-pressed to call any of it efficient.
This is not a temporary problem with a known fix. The way modern AI runs on the chips that exist today, the walking is the architecture. The industry has spent the last fifteen years getting the cooks to walk faster, each new generation of chip a faster cook, and the pantry is still the pantry and the fridge is still the fridge.
Everybody is making the hamster wheel faster.
What we built
We did not make a faster hamster wheel.
We built a chip where the math is the wiring. There is nothing to fetch and nothing to walk to, because the answer is not assembled out of numbers shuttled through memory; it is what the chip does when you give it a question. The walking is gone, and most of the electricity that used to move data now does not need to move at all.
The numbers that fall out of this are not subtle. A current top-of-the-line GPU answering one question burns about seven hundred watts. The next generation burns a thousand. Our chip does the same work on three watts, which is roughly the LED bulb in your refrigerator.
The Virginia datacenter the size of a town becomes, on this architecture, an appliance the size of a closet. The things ChatGPT does today, your phone could do without sending anything to a server and without burning the battery. A satellite small enough to launch on a rideshare can carry AI in three watts of payload, where today the same satellite has to beam its data down to a datacenter on the ground and wait for the answer to come back.
The chip also trains itself. There is no separate building somewhere else where the model is taught and then shipped to the inference building. The teaching and the answering happen on the same silicon, because the silicon is the model.
Why it matters now
The world is currently planning to spend roughly six hundred billion dollars over this decade to build more of the buildings outside Ashburn. Inference demand is growing ten times faster than they can pour the concrete. There is no version of that race that ends with enough buildings.
We are not making the hamster wheel faster. We are getting off the wheel.