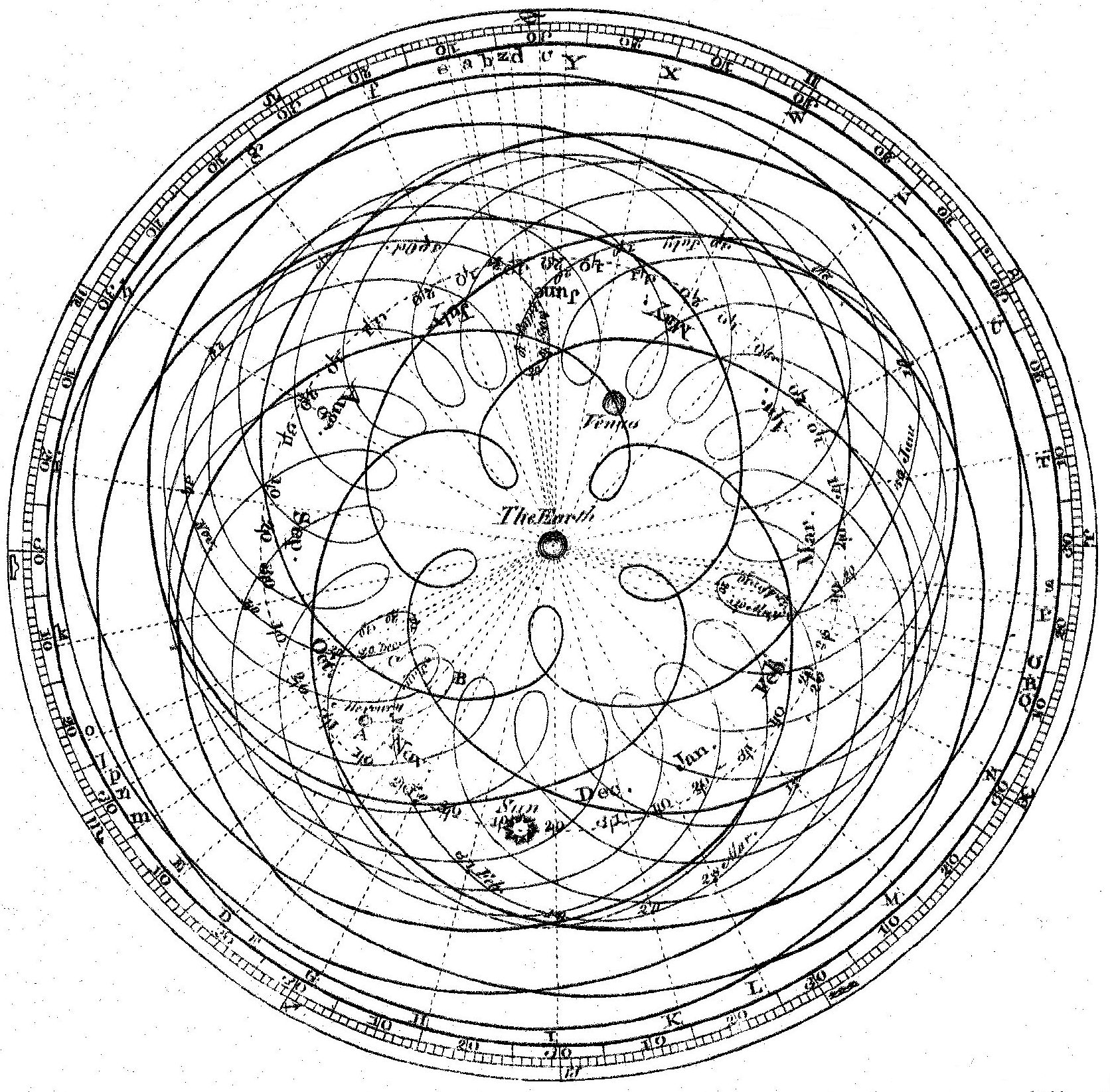
Apparent motion of the Sun, Mercury, and Venus from Earth, illustrating Ptolemaic epicycles. James Ferguson, after Cassini and Long, engraved by Andrew Bell for the first edition of the Encyclopædia Britannica, 1771. Public domain via Wikimedia Commons.
LeCun Is Right About the Destination
Each version of JEPA strips another epicycle. The direction of travel is unambiguous, and its endpoint is not a better loss function.

Alex Morisse
Founder & CEO · April 11, 2026 · 8 min read
There is a story engineers tell about the automatic transmission. In the late 1950s, somebody figured out that the optimal gear-shift policy for a hydraulic torque converter was itself a hydraulic equation, and so they built the valve body: a hunk of aluminum with channels and ports and a governor ball that spins on the output shaft, such that the fluid pressure at each port is exactly the function of speed and load that the math says it should be. The valve body does not compute the gear-shift decision. The valve body is the gear-shift decision, expressed in geometry. Nobody has ever shipped a firmware update to a valve body. The physics does not need a patch.

I think about this story a lot when I read papers from Yann LeCun and his collaborators.
LeCun has been saying for four years, with increasing insistence, that the current approach to AI is wrong at the foundations. Prediction in pixel space is wasteful. Representations should live in a compact latent space. The objective should be energy-based, not likelihood-based. A world model should work by relaxing to a low-energy state, not by sampling tokens from a probability distribution one at a time. He calls the programme JEPA, for Joint-Embedding Predictive Architecture, and it has been getting simpler with each iteration in a way that should make everyone pay attention.

The earlier JEPA versions needed five or six loss terms, stop-gradient gymnastics to prevent representation collapse, careful scheduling of which components get trained when. Each new version peels off one more piece of scaffolding. The latest one, LeWorldModel (arXiv 2603.19312), needs two objectives: predict the next embedding in a compact latent space, and regularise those latents to be Gaussian-distributed. The architecture does the rest. Fifteen million parameters, trains on a single GPU in a matter of hours, plans forty-eight times faster than foundation-model-based planners on physical reasoning tasks, and its latent space spontaneously learns to flag physically implausible transitions as high-energy outliers.
Forty-eight times faster. Fifteen million parameters. Two loss terms. The system is getting more powerful as it gets simpler, which is what happens when you start removing the wrong assumptions.
JEPA is one strand of a larger architecture LeCun has been sketching for years, in which a world model sits alongside cost modules, planners, and an actor that closes the loop with the environment. But it is the strand where the substrate question is sharpest, because the dynamics being asked of the network are the ones a physical system would do for free.
What LeCun is converging on, I think, is physics, though he would probably say it differently. The Gaussian regulariser that LeWorldModel has to engineer as an explicit loss term is what happens for free at thermal equilibrium in the right kind of physical substrate. You don't add it as a penalty, you don't schedule it against the prediction loss, you don't worry about whether it will collapse under training pressure. It falls out of the thermodynamics. The substrate enforces it because that is what the substrate does.
The next-embedding prediction loss, similarly, is forward-looking: the system should predict what comes next, not just describe what has already happened. In a physical substrate, this is not a loss function computed in finite differences and then differentiated. It is the native behaviour of a system relaxing toward low-energy states. LeCun is trying to get a digital neural network trained by gradient descent to behave like a substrate that natively relaxes toward low-energy predictions with Gaussian-distributed latent states. Each JEPA version is a new attempt to bend gradient descent into that shape. Each version is closer. Each version is also more elaborate than the actual thing it is trying to approximate.
This is the Ptolemaic situation. Ptolemy's model of planetary motion worked, and it got better every time someone added an epicycle. The predictions improved with each refinement, the mathematics got more involved, and for more than a thousand years the model went on calling eclipses correctly. The direction of travel looked like progress because each step really was reducing the residual error against the sky. It was not progress, it was a system being held in place by an assumption nobody was willing to touch.
The assumption was that celestial motion had to be built out of uniform circles around the Earth. Once that was fixed, every observation that refused to fit a circle had to be accommodated by another circle. The epicycle was the only move on the board. You could not get rid of epicycles by adding more of them. They were what the wrong premise forced the model to keep producing.
Then Copernicus removed the Earth from the centre and suddenly you needed far fewer epicycles. Kepler found the ellipse and the rest of them vanished. Newton wrote down one equation linking force, mass, and gravity, and the orbits fell out of first principles. The scaffolding of epicycles, deferents, and equants stopped being astronomy. It became a record of the wrong question being answered well.
Epicycles are cheats. Not intellectually dishonest, but the move you make when you have committed to a premise and the data refuses to cooperate, so you bend the model instead of the premise. Every epicycle is a vote against the assumption it is shoring up.
LeCun is doing the opposite of adding epicycles, which is how you know the programme is healthy. He is removing them, one per JEPA generation, and the thing is getting better as he does. The direction of travel is unambiguous. The endpoint he is approaching is a system whose latent states are naturally Gaussian, whose predictions naturally minimise a free energy, whose representations naturally separate the plausible from the implausible, and which does all of this without an explicit loss function because that is just what it does when you let it run. That endpoint is not a better neural network architecture. Its a physical substrate.
We are building the endpoint.
Not a better neural network, not a simpler loss function, not a faster GPU kernel, not an analog accelerator that runs the same computation in fewer joules. The substrate whose native dynamics satisfy, without being asked, the two properties that LeWorldModel has to engineer explicitly into its training objective. The silicon learns. Not because we wrote a learning algorithm, but because the physics of the substrate is the learning algorithm, in the same way that the valve body doesn't compute fluid pressure, it is fluid pressure, in aluminum.
The training-inference distinction, which we treat as fundamental, is an artifact of the simulation paradigm. You train on one machine, you deploy to another, you carry weights across the gap. In a substrate where learning is the dynamics and the dynamics are always running, that distinction dissolves. The machine writes its own program by running.
There is no separate encoder trained on a proxy task and then frozen. The encoder is the substrate, in the same way that the valve body's channels are the algorithm rather than a description of the algorithm. This was always the right architecture. It is just hard to build.
Lagrange gave us the principle of least action in 1788. Boltzmann wrote down the entropy in 1877. Helmholtz wrote down the free energy in 1882. Every few decades, artificial intelligence rediscovers one of these equations through the side door, packages it as a novel training objective, and publishes it with a new acronym. The equations don't change. The physicists who wrote them down two centuries ago were describing something real about how systems that interact with their environment organize themselves over time, how they represent the world, how they predict what comes next, how they learn.

LeCun is right that this is where AI needs to go. He is right about the destination. The question is whether you get there by adding better loss functions to gradient descent indefinitely, or whether you build the substrate that was always there in the equations, waiting to be expressed in matter rather than simulated on a chip that was designed to do something else.
The valve body did not emerge from a really good simulation of fluid dynamics running on a microcontroller. Someone put the aluminum where the physics wanted it.
We are doing that for learning.
Further reading
- Maes, Le Lidec, Scieur, LeCun, Balestriero — LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels (2026). The two-loss-term JEPA paper. Project page: le-wm.github.io.
- Yann LeCun — A Path Towards Autonomous Machine Intelligence (2022). The position paper that introduced the JEPA programme and the case against autoregressive generative AI.
- I-JEPA: The first AI model based on Yann LeCun's vision — Meta AI blog (2023). The first concrete embedding-space model in the programme.
- Boltzmann machine — Hinton & Sejnowski (1985), an early proposal for a learning system whose dynamics are explicitly thermal.